Spark transformations and actions pdf
Transformations in RDD Actions in RDD Loading data in RDD Saving data through RDD Key-Value Pair RDD MapReduce and Pair RDD Operations Spark and Hadoop Integration-HDFS Handling Sequence Files and Partitioner Spark Hadoop Integration-Yarn . Chapter 6 : Spark Streaming And Mllib Spark Streaming Architecture First Spark Streaming Program Transformations in Spark Streaming Fault …
Spark Driver is the program that runs on the master node of the machine and declares transformations and actions on data RDDs. In simple terms, driver in Spark creates SparkContext, connected to a given Spark Master. The driver also delivers the RDD graphs to Master, where the standalone
Code Snippet1 work’s fine and populates the database…the second code snippet doesn’t work.we are newbie’s to spark and would love to know the reason behind it and the way to get it working ?…..the reason we are experimenting ( we know it’s a transformation and foreachRdd is an action) is foreachRdd is very slow for our use case with heavy load on a cluster and we found that map is …
Spark is lazy, so nothing will be executed unless you call some transformation or action that will trigger job creation and execution. Look at the following snippet of the word-count example. Look at the following snippet of the word-count example.
Dig in and get your hands dirty with one of the hottest data processing engines today. A great guide. Jonathan Sharley, Pandora Media. Spark in Action teaches you the theory and skills you need to effectively handle batch and streaming data using Spark.
Spark Core Spark Streaming MLlib GraphX RDD API DataFrames API and Spark SQL Workloads . Driver Program Ex RDD W RDD T T Ex RDD W RDD T T Worker Machine Worker Machine . Resilient Distributed Datasets (RDDs) •Write programs in terms of operations on distributed data •Partitioned collections of objects spread across a cluster •Diverse set of parallel transformations and actions …
3.1.3 SparkCL Transformations and Actions Standard Spark actions such as Map and transformations such as Reduce needed to be ported to the new framework.
functions to Spark’s transformations and actions In Java, we pass objects of the classes that implement one of the Spark’s function interfaces Each class implementing a Spark’s function interface is characterized by the call method The call method contains the “function” that we want to pass to a transformation or to an action 42 . 10/04/2018 22 There are many Spark’s function
Types of spark operations There are Three types of operations on RDDs: Transformations, Actions and Shuffles. The most expensive operations are those the require
Key constructs: Resilient Distributed Datasets (RDDs), Transformations, Actions, Spark Driver programs, SparkContext and how applications deployed to a Spark cluster utilize the parallel nature of Spark.
Actions: Actions refer to an operation which also applies on RDD, that instructs Spark to perform computation and send the result back to driver. This is an example of action. This is an example of action.
The structure of a Spark program at higher level is – RDD’s are created from the input data and new RDD’s are derived from the existing RDD’s using different transformations, after which an action is performed on the data. In any spark program, the DAG operations are created by default and whenever the driver runs the Spark DAG will be converted into a physical execution plan.
This Lecture” Programming Spark” Resilient Distributed Datasets (RDDs)” Creating an RDD” Spark Transformations and Actions” Spark Programming Model”
Databricks would like to give a special thanks to Jeff Thomspon for contributing 67 visual diagrams depicting the Spark API under the MIT license to the Spark
Here is a cheat sheet that I put together that might help you out: Apache Spark Cheat Sheet (PDF) or Apache Spark Cheat Sheet (HTML) Transformations and Actions are the first two items listed. The benefit here is that Spark figures out what work MUST occur and …
Spark concepts such as the Resilient Distributed Dataset (RDD), interacting with Spark using the shell, implementing common processing patterns, practical data engineering/analysis approaches using Spark…
functions to Spark’s transformations and actions In Java, we pass objects of the classes that implement one of the Spark’s function interfaces Each class implementing a Spark’s function interface is characterized by the call method The call method contains the “function” that we want to pass to a transformation or to an action There are many Spark’s function interfaces The
RDD Programming Guide Spark 2.4.0 Documentation
https://youtube.com/watch?v=YbxEvbunhY8

The Anatomy Of Transformations Medium
DAG (Directed Acyclic Graph) and Physical Execution Plan are core concepts of Apache Spark. Understanding these can help you write more efficient Spark …
Everyone will receive a username/password for one of the Databricks Cloud shards. Use your laptop and browser to login there.! We find that cloud-based notebooks are a simple way
The Essential Apache Spark Developer Cheat Sheet Apache Spark is a powerful open source processing engine built around speed, ease of use, and sophisticated analytics. This developer cheat sheet dives into resources for Spark developers, and includes a list of Spark transformations, actions, and persistence methods.
In this post, we’re going to cover the architecture of Spark and basic transformations and actions using a real dataset. If you want to write and run your own Spark code, check out the interactive version of this post on Dataquest .
At a high level, every Spark application consists of a driver program that runs the user’s main function and executes various parallel operations on a cluster. The main abstraction Spark provides is a distributed dataset, which is a collection of elements partitioned across the nodes of the cluster
I tried out the transformations and actions but most importantly had fun while doing so because of the little notes of humor that you had left in between. I’m glad google led …

The doctests serve as simple usage examples and are a lightweight way to test new RDD transformations and actions. The unittests are used for more involved testing, such as testing job cancellation. The unittests are used for more involved testing, such as testing job cancellation.
partitions and perform computations and transformations using the contained data. Whenever a part of a RDD or an entire RDD is lost, the system is able to reconstruct the data of lost partitions by using lineage information.
You go back to stage 1 (the spark), set (beyond SMART) goals, and prepare yourself for another transformation. Success is a result of daily actions… Design your daily checklist for high

Feature extraction and transformation Used in selecting a subset of relevant features (variables, predictors) for use in model construction. Frequent pattern mining
From 0 to 1 : Spark for Data Science with Python 4.3 (251 ratings) Pair RDDs are special types of RDDs where every record is a key value pair. All normal actions and transformations apply to these in addition to some special ones. Special Transformations and Actions 14:44 Pair RDDs are useful to get information on a per-key basis. Sales per city, delays per airport etc. Average delay per
Transformation and action. In previous blog you know that transformation functions produce a new Resilient Distributed Dataset (RDD). Resilient distributed datasets are Spark’s main programming
27/10/2016 · What is Spark, RDD, DataFrames, Spark Vs Hadoop? Spark Architecture, Lifecycle with simple Example – Duration: 26:17. Tech Primers 66,496 views
With Spark, you can tackle big datasets quickly through simple APIs in Python, Java, and Scala. This edition includes new information on Spark SQL, Spark Streaming, setup, and Maven coordinates. This edition includes new information on Spark SQL, Spark Streaming, setup, and Maven coordinates.
Spark Driver is the program that runs on the master node of the machine and declares transformations and actions on data RDDs. In simple terms, driver in Spark creates SparkContext, connected to a given Spark …
Compose Spark jobs from actions and transformations Create highly concurrent Spark programs by leveraging immutability Ways to avoid the most expensive operation in the Spark API—Shuffle
visual diagrams depicting the Spark API under the MIT license to the Spark community. Jeff’s original, creative work can be found here and you can read more about
Apache Spark DataFrames for Large Scale Data Science
Introduction to big data Analytics using Spark . Agenda A slide on Compute Canada Review of Bigdata Review hands-on Mapreduce: why we need spark Spark Internals Spark Hands HBase Internals (not fully covered in the first workshop) HBase hands-on . Compute Canada: A national Platform for Advance Research Computing Support and experts in advanced research computing Many clusters …
Matei&Zaharia& & UC&Berkeley& & www.spark4project.org&& Advanced(Spark Features(UC&BERKELEY&
The book starts with an introduction to Spark, after which the Spark fundamentals are introduced. In practical terms, this means the spark-in-action VM, using the Spark shell and writing apps in Spark, the basics of RDD (resilient distributed dataset) actions, transformations, and double RDD functions.
Spark provides two kinds of operations, one is transformation and another is action. Transformation and Actions What is Transformation: Transformation converts one RDD to another RDD.
SQL queries can be easily translated into Spark transformation and actions, as demonstrated in Shark and Spark SQL. In fact, many primitive transformations and actions are …
This Lecture Resilient Distributed Datasets (RDDs) Creating an RDD Spark RDD Transformations and Actions Spark RDD Programming Model Spark Shared Variables
Spark SQL: Relational Data Processing in Spark Michael Armbrusty, Reynold S. Xiny, Cheng Liany, Yin Huaiy, Davies Liuy, Joseph K. Bradleyy, Xiangrui Mengy, Tomer
Transformations and Actions Databricks
Spark 2.4.0 is built and distributed to work with Scala 2.11 by default. (Spark can be built to work with other versions of Scala, too.) To write applications in Scala, you will need to use a compatible Scala version (e.g. 2.11.X).
Spark Overview RDD provides full recovery by backing up transformations from stable storage rather than backing up the data itself. RDDs can be stored in memory and thus are often much faster.
Recently updated for Spark 1.3, this book introduces Apache Spark, the open source cluster computing system that makes data analytics fast to write and fast to run. With Spark, you can tackle big datasets quickly through simple APIs in Python, Java, and Scala. This edition includes new information on Spark SQL, Spark Streaming, setup, and Maven coordinates.
Big Data Analysis with Apache Spark edX

Hadoop architecture and ecosystem Polito
https://youtube.com/watch?v=v-RaoueUoUE
Spark Fundamentals II Building on your foundational knowledge of Spark, take this opportunity to move your skills to the next level. With a focus on Spark Resilient Distributed Data Set operations this course exposes you to concepts that are critical to your success in this field.
The transformations are only computed when an action requires a result to be returned to the driver program. With these two types of RDD operations, Spark can run more efficiently: a dataset created through map() operation will be used in a consequent reduce() operation and will return only the result of the the last reduce function to the driver.
What is SPARK (II) • Three modes of execution – Spark shell – Spark scripts – Spark code • API defined for multiple languages – Scala – Python – Java A couple of words on Scala • Object-oriented language: everything is an object and every operation is a method-call. • Scala is also a functional language – Functions are first class values – Can be passed as arguments to
Spark Tutorials with… by Todd McGrath [Leanpub PDF/iPad

Apache Spark RDD Transformations and Actions
sequence of Spark transformations that can be executed in parallel and that are concluded by an action. This sequence of operations is then automatically transformed …
these data analysis transformations and actions through an interactive terminal, which comes packaged with Spark. Spark driver programs run at a central location and oper-
Spark packages are available for many different HDFS versions Spark runs on Windows and UNIX-like systems such as Linux and MacOS The easiest setup is local, but the real power of …
Spark SQL Overview. Spark SQL integrates relational processing with Spark’s functional programming. It provides support for various data sources and makes it possible to weave SQL queries with code transformations thus resulting in a very powerful tool.
Figure 8 shows how Apache Spark executes a job on a cluster The Master controls how data is partitioned, and it takes advantage of data locality while keeping track …
Transformations, Actions, Laziness Actions cause the execution of the query. What, exactly does “execution of the query” mean? It means: •Spark initiates a distributed read of the data source •The data flows through the transformations (the RDDs resulting from the Catalyst query plan) •The result of the action is pulled back into the driver JVM. 25. All Actions on a DataFrame 26. 27. 28
Ans: An action is an operation that triggers execution of RDD transformations and returns a value (to a Spark driver – the user program). They trigger execution of RDD transformatio ns to
22/11/2015 · By http://www.HadoopExam.com For Full length Apache Spark Session , Please visit www.HadoopExam.com.
Apache Spark is written in Scala programming language that compiles the program code into byte code for the JVM for spark big data processing. The open source community has developed a wonderful utility for spark python big data processing known as PySpark. PySpark helps data scientists interface with Resilient Distributed Datasets in apache spark and python.Py4J is a popularly library
Actions are operations (such as reduce, count, first, and so on) that return a value after running a computation on an RDD. Transformations in Spark are “lazy”, meaning that they do not compute their results right away. Instead, they just “remember” the operation to be performed and the dataset (e.g., file) to which the operation is to be performed. The transformations are only
What is SPARK? Computer Science
The concept of lazy execution is described and we outline various transformations and actions specific to RDDs and DataFrames. Finally, we show you how to use SQL to interact with DataFrames. By the end of this tutorial, you will have learned how to process data using Spark DataFrames and mastered data collection techniques by distributed data processing.
6sdun 2yhuylhz *rdo hdvlo zrun zlwk odujh vfdoh gdwd lq whupv ri wudqvirupdwlrqv rq glvwulexwhg gdwd 7udglwlrqdo glvwulexwhg frpsxwlqj sodwirupv vfdoh zhoo exw kdyh olplwhg ,v
A fine grained update would be an update to one record in a database whereas coarse grained is generally functional operators (like used in spark) for example map, reduce, flatMap, join.
Table 2 lists the main RDD transformations and actions available in Spark. We give the signature of each oper-ation, showing type parameters in square brackets. Re- call that transformations are lazy operations that define a new RDD, while actions launch a computation to return a value to the program or write data to external storage. Notethatsomeoperations,suchas join,areonlyavail-able on
It is essential you are comfortable with the Spark concepts of Resilient Distributed Datasets (RDD), Transformations, Actions. If you need more information on these subjects from a non-Scala point of view, it is suggested to start at the Spark Tutorial page first and then return to this page. In the following tutorials, the Spark fundaments are covered from a Scala perspective.
![]()
Spark DataFrames API is a distributed collection of data organized into named columns and was created to support modern big data and data science applications. As an extension to the existing RDD API, DataFrames features seamless integration with all big data tooling and infrastructure via Spark.
This is 2nd post in Apache Spark 5 part blog series. In the previous blog we looked at why we needed tool like Spark, what makes it faster cluster computing system and its core components. In this blog we will work with actual data using Spark core API: RDDs, transformations and actions. RDD
An Engine for Large-Scale Data Processing. Introduces Spark, explains its place in big data, walks through setup and creation of a Spark application, and explains commonly used actions and operations.
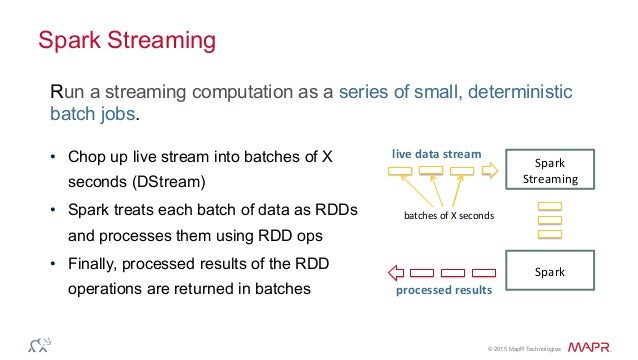
https://youtube.com/watch?v=MlbpXsO0AwU
PySpark Internals Spark – Apache Software Foundation
Getting Started with Apache Spark MapR
Apache Spark with Scala By Example Udemy
Spark and Resilient Distributed Datasets LAMSADE
APACHE SPARK DEVELOPER INTERVIEW QUESTIONS SET
Transformations and Actions Databricks
There are Three types of operations on RDDs
Spark SQL Overview. Spark SQL integrates relational processing with Spark’s functional programming. It provides support for various data sources and makes it possible to weave SQL queries with code transformations thus resulting in a very powerful tool.
Databricks would like to give a special thanks to Jeff Thomspon for contributing 67 visual diagrams depicting the Spark API under the MIT license to the Spark
6sdun 2yhuylhz *rdo hdvlo zrun zlwk odujh vfdoh gdwd lq whupv ri wudqvirupdwlrqv rq glvwulexwhg gdwd 7udglwlrqdo glvwulexwhg frpsxwlqj sodwirupv vfdoh zhoo exw kdyh olplwhg ,v
these data analysis transformations and actions through an interactive terminal, which comes packaged with Spark. Spark driver programs run at a central location and oper-
Manning Spark in Action
Apache Spark flatmap Transformation Tutorial YouTube
SQL queries can be easily translated into Spark transformation and actions, as demonstrated in Shark and Spark SQL. In fact, many primitive transformations and actions are …
Transformations in RDD Actions in RDD Loading data in RDD Saving data through RDD Key-Value Pair RDD MapReduce and Pair RDD Operations Spark and Hadoop Integration-HDFS Handling Sequence Files and Partitioner Spark Hadoop Integration-Yarn . Chapter 6 : Spark Streaming And Mllib Spark Streaming Architecture First Spark Streaming Program Transformations in Spark Streaming Fault …
This Lecture Resilient Distributed Datasets (RDDs) Creating an RDD Spark RDD Transformations and Actions Spark RDD Programming Model Spark Shared Variables
Spark packages are available for many different HDFS versions Spark runs on Windows and UNIX-like systems such as Linux and MacOS The easiest setup is local, but the real power of …
It is essential you are comfortable with the Spark concepts of Resilient Distributed Datasets (RDD), Transformations, Actions. If you need more information on these subjects from a non-Scala point of view, it is suggested to start at the Spark Tutorial page first and then return to this page. In the following tutorials, the Spark fundaments are covered from a Scala perspective.
Spark Tutorial @ DAO
Apache Spark RDD Transformations and Actions
DAG (Directed Acyclic Graph) and Physical Execution Plan are core concepts of Apache Spark. Understanding these can help you write more efficient Spark …
The doctests serve as simple usage examples and are a lightweight way to test new RDD transformations and actions. The unittests are used for more involved testing, such as testing job cancellation. The unittests are used for more involved testing, such as testing job cancellation.
Spark Core Spark Streaming MLlib GraphX RDD API DataFrames API and Spark SQL Workloads . Driver Program Ex RDD W RDD T T Ex RDD W RDD T T Worker Machine Worker Machine . Resilient Distributed Datasets (RDDs) •Write programs in terms of operations on distributed data •Partitioned collections of objects spread across a cluster •Diverse set of parallel transformations and actions …
partitions and perform computations and transformations using the contained data. Whenever a part of a RDD or an entire RDD is lost, the system is able to reconstruct the data of lost partitions by using lineage information.
22/11/2015 · By http://www.HadoopExam.com For Full length Apache Spark Session , Please visit www.HadoopExam.com.
Transformations, Actions, Laziness Actions cause the execution of the query. What, exactly does “execution of the query” mean? It means: •Spark initiates a distributed read of the data source •The data flows through the transformations (the RDDs resulting from the Catalyst query plan) •The result of the action is pulled back into the driver JVM. 25. All Actions on a DataFrame 26. 27. 28
Hive on Spark Apache Hive – Apache Software Foundation
What are DAG and Physical Execution Plan in Apache Spark
Spark Driver is the program that runs on the master node of the machine and declares transformations and actions on data RDDs. In simple terms, driver in Spark creates SparkContext, connected to a given Spark Master. The driver also delivers the RDD graphs to Master, where the standalone
Spark Core Spark Streaming MLlib GraphX RDD API DataFrames API and Spark SQL Workloads . Driver Program Ex RDD W RDD T T Ex RDD W RDD T T Worker Machine Worker Machine . Resilient Distributed Datasets (RDDs) •Write programs in terms of operations on distributed data •Partitioned collections of objects spread across a cluster •Diverse set of parallel transformations and actions …
A fine grained update would be an update to one record in a database whereas coarse grained is generally functional operators (like used in spark) for example map, reduce, flatMap, join.
Spark 2.4.0 is built and distributed to work with Scala 2.11 by default. (Spark can be built to work with other versions of Scala, too.) To write applications in Scala, you will need to use a compatible Scala version (e.g. 2.11.X).
Here is a cheat sheet that I put together that might help you out: Apache Spark Cheat Sheet (PDF) or Apache Spark Cheat Sheet (HTML) Transformations and Actions are the first two items listed. The benefit here is that Spark figures out what work MUST occur and …
Types of spark operations There are Three types of operations on RDDs: Transformations, Actions and Shuffles. The most expensive operations are those the require
3.1.3 SparkCL Transformations and Actions Standard Spark actions such as Map and transformations such as Reduce needed to be ported to the new framework.
Ans: An action is an operation that triggers execution of RDD transformations and returns a value (to a Spark driver – the user program). They trigger execution of RDD transformatio ns to
Everyone will receive a username/password for one of the Databricks Cloud shards. Use your laptop and browser to login there.! We find that cloud-based notebooks are a simple way
Table 2 lists the main RDD transformations and actions available in Spark. We give the signature of each oper-ation, showing type parameters in square brackets. Re- call that transformations are lazy operations that define a new RDD, while actions launch a computation to return a value to the program or write data to external storage. Notethatsomeoperations,suchas join,areonlyavail-able on
Actions are operations (such as reduce, count, first, and so on) that return a value after running a computation on an RDD. Transformations in Spark are “lazy”, meaning that they do not compute their results right away. Instead, they just “remember” the operation to be performed and the dataset (e.g., file) to which the operation is to be performed. The transformations are only
This Lecture Resilient Distributed Datasets (RDDs) Creating an RDD Spark RDD Transformations and Actions Spark RDD Programming Model Spark Shared Variables
Dig in and get your hands dirty with one of the hottest data processing engines today. A great guide. Jonathan Sharley, Pandora Media. Spark in Action teaches you the theory and skills you need to effectively handle batch and streaming data using Spark.
SQL queries can be easily translated into Spark transformation and actions, as demonstrated in Shark and Spark SQL. In fact, many primitive transformations and actions are …
Apache Spark GitHub Pages
DICE Verification Tools Final Version
The book starts with an introduction to Spark, after which the Spark fundamentals are introduced. In practical terms, this means the spark-in-action VM, using the Spark shell and writing apps in Spark, the basics of RDD (resilient distributed dataset) actions, transformations, and double RDD functions.
This Lecture” Programming Spark” Resilient Distributed Datasets (RDDs)” Creating an RDD” Spark Transformations and Actions” Spark Programming Model”
Actions are operations (such as reduce, count, first, and so on) that return a value after running a computation on an RDD. Transformations in Spark are “lazy”, meaning that they do not compute their results right away. Instead, they just “remember” the operation to be performed and the dataset (e.g., file) to which the operation is to be performed. The transformations are only
Transformations, Actions, Laziness Actions cause the execution of the query. What, exactly does “execution of the query” mean? It means: •Spark initiates a distributed read of the data source •The data flows through the transformations (the RDDs resulting from the Catalyst query plan) •The result of the action is pulled back into the driver JVM. 25. All Actions on a DataFrame 26. 27. 28
Code Snippet1 work’s fine and populates the database…the second code snippet doesn’t work.we are newbie’s to spark and would love to know the reason behind it and the way to get it working ?…..the reason we are experimenting ( we know it’s a transformation and foreachRdd is an action) is foreachRdd is very slow for our use case with heavy load on a cluster and we found that map is …
Transformation and action. In previous blog you know that transformation functions produce a new Resilient Distributed Dataset (RDD). Resilient distributed datasets are Spark’s main programming
Apache Spark DZone – Refcardz
Spark Tutorials with… by Todd McGrath [Leanpub PDF/iPad
What is SPARK (II) • Three modes of execution – Spark shell – Spark scripts – Spark code • API defined for multiple languages – Scala – Python – Java A couple of words on Scala • Object-oriented language: everything is an object and every operation is a method-call. • Scala is also a functional language – Functions are first class values – Can be passed as arguments to
You go back to stage 1 (the spark), set (beyond SMART) goals, and prepare yourself for another transformation. Success is a result of daily actions… Design your daily checklist for high
Spark 2.4.0 is built and distributed to work with Scala 2.11 by default. (Spark can be built to work with other versions of Scala, too.) To write applications in Scala, you will need to use a compatible Scala version (e.g. 2.11.X).
Feature extraction and transformation Used in selecting a subset of relevant features (variables, predictors) for use in model construction. Frequent pattern mining
Databricks would like to give a special thanks to Jeff Thomspon for contributing 67 visual diagrams depicting the Spark API under the MIT license to the Spark
DAG (Directed Acyclic Graph) and Physical Execution Plan are core concepts of Apache Spark. Understanding these can help you write more efficient Spark …
Titian Data Provenance Support in Spark VLDB
From 0 to 1 Spark for Data Science with Python Udemy
Transformation and action. In previous blog you know that transformation functions produce a new Resilient Distributed Dataset (RDD). Resilient distributed datasets are Spark’s main programming
sequence of Spark transformations that can be executed in parallel and that are concluded by an action. This sequence of operations is then automatically transformed …
Spark Overview RDD provides full recovery by backing up transformations from stable storage rather than backing up the data itself. RDDs can be stored in memory and thus are often much faster.
6sdun 2yhuylhz *rdo hdvlo zrun zlwk odujh vfdoh gdwd lq whupv ri wudqvirupdwlrqv rq glvwulexwhg gdwd 7udglwlrqdo glvwulexwhg frpsxwlqj sodwirupv vfdoh zhoo exw kdyh olplwhg ,v
3.1.3 SparkCL Transformations and Actions Standard Spark actions such as Map and transformations such as Reduce needed to be ported to the new framework.
Spark is lazy, so nothing will be executed unless you call some transformation or action that will trigger job creation and execution. Look at the following snippet of the word-count example. Look at the following snippet of the word-count example.
Spark SQL Overview. Spark SQL integrates relational processing with Spark’s functional programming. It provides support for various data sources and makes it possible to weave SQL queries with code transformations thus resulting in a very powerful tool.
Transformations in RDD Actions in RDD Loading data in RDD Saving data through RDD Key-Value Pair RDD MapReduce and Pair RDD Operations Spark and Hadoop Integration-HDFS Handling Sequence Files and Partitioner Spark Hadoop Integration-Yarn . Chapter 6 : Spark Streaming And Mllib Spark Streaming Architecture First Spark Streaming Program Transformations in Spark Streaming Fault …
Spark and Resilient Distributed Datasets LAMSADE
There are Three types of operations on RDDs
6sdun 2yhuylhz *rdo hdvlo zrun zlwk odujh vfdoh gdwd lq whupv ri wudqvirupdwlrqv rq glvwulexwhg gdwd 7udglwlrqdo glvwulexwhg frpsxwlqj sodwirupv vfdoh zhoo exw kdyh olplwhg ,v
Transformations in RDD Actions in RDD Loading data in RDD Saving data through RDD Key-Value Pair RDD MapReduce and Pair RDD Operations Spark and Hadoop Integration-HDFS Handling Sequence Files and Partitioner Spark Hadoop Integration-Yarn . Chapter 6 : Spark Streaming And Mllib Spark Streaming Architecture First Spark Streaming Program Transformations in Spark Streaming Fault …
Dig in and get your hands dirty with one of the hottest data processing engines today. A great guide. Jonathan Sharley, Pandora Media. Spark in Action teaches you the theory and skills you need to effectively handle batch and streaming data using Spark.
27/10/2016 · What is Spark, RDD, DataFrames, Spark Vs Hadoop? Spark Architecture, Lifecycle with simple Example – Duration: 26:17. Tech Primers 66,496 views
Ans: An action is an operation that triggers execution of RDD transformations and returns a value (to a Spark driver – the user program). They trigger execution of RDD transformatio ns to
Matei&Zaharia& & UC&Berkeley& & www.spark4project.org&& Advanced(Spark Features(UC&BERKELEY&
SQL queries can be easily translated into Spark transformation and actions, as demonstrated in Shark and Spark SQL. In fact, many primitive transformations and actions are …
Transformations, Actions, Laziness Actions cause the execution of the query. What, exactly does “execution of the query” mean? It means: •Spark initiates a distributed read of the data source •The data flows through the transformations (the RDDs resulting from the Catalyst query plan) •The result of the action is pulled back into the driver JVM. 25. All Actions on a DataFrame 26. 27. 28
Recently updated for Spark 1.3, this book introduces Apache Spark, the open source cluster computing system that makes data analytics fast to write and fast to run. With Spark, you can tackle big datasets quickly through simple APIs in Python, Java, and Scala. This edition includes new information on Spark SQL, Spark Streaming, setup, and Maven coordinates.
Spark Programming Guide · mesos/spark Wiki · GitHub
Learning Spark O’Reilly Media
In this post, we’re going to cover the architecture of Spark and basic transformations and actions using a real dataset. If you want to write and run your own Spark code, check out the interactive version of this post on Dataquest .
What is SPARK (II) • Three modes of execution – Spark shell – Spark scripts – Spark code • API defined for multiple languages – Scala – Python – Java A couple of words on Scala • Object-oriented language: everything is an object and every operation is a method-call. • Scala is also a functional language – Functions are first class values – Can be passed as arguments to
I tried out the transformations and actions but most importantly had fun while doing so because of the little notes of humor that you had left in between. I’m glad google led …
Actions are operations (such as reduce, count, first, and so on) that return a value after running a computation on an RDD. Transformations in Spark are “lazy”, meaning that they do not compute their results right away. Instead, they just “remember” the operation to be performed and the dataset (e.g., file) to which the operation is to be performed. The transformations are only
Spark 2.4.0 is built and distributed to work with Scala 2.11 by default. (Spark can be built to work with other versions of Scala, too.) To write applications in Scala, you will need to use a compatible Scala version (e.g. 2.11.X).
Spark SQL Overview. Spark SQL integrates relational processing with Spark’s functional programming. It provides support for various data sources and makes it possible to weave SQL queries with code transformations thus resulting in a very powerful tool.
Apache Spark Introduction Examples and Use Cases Toptal
Learning Spark [Book] oreilly.com
Compose Spark jobs from actions and transformations Create highly concurrent Spark programs by leveraging immutability Ways to avoid the most expensive operation in the Spark API—Shuffle
Spark provides two kinds of operations, one is transformation and another is action. Transformation and Actions What is Transformation: Transformation converts one RDD to another RDD.
Spark DataFrames API is a distributed collection of data organized into named columns and was created to support modern big data and data science applications. As an extension to the existing RDD API, DataFrames features seamless integration with all big data tooling and infrastructure via Spark.
This Lecture Resilient Distributed Datasets (RDDs) Creating an RDD Spark RDD Transformations and Actions Spark RDD Programming Model Spark Shared Variables
DAG (Directed Acyclic Graph) and Physical Execution Plan are core concepts of Apache Spark. Understanding these can help you write more efficient Spark …
functions to Spark’s transformations and actions In Java, we pass objects of the classes that implement one of the Spark’s function interfaces Each class implementing a Spark’s function interface is characterized by the call method The call method contains the “function” that we want to pass to a transformation or to an action There are many Spark’s function interfaces The
It is essential you are comfortable with the Spark concepts of Resilient Distributed Datasets (RDD), Transformations, Actions. If you need more information on these subjects from a non-Scala point of view, it is suggested to start at the Spark Tutorial page first and then return to this page. In the following tutorials, the Spark fundaments are covered from a Scala perspective.
This Lecture” Programming Spark” Resilient Distributed Datasets (RDDs)” Creating an RDD” Spark Transformations and Actions” Spark Programming Model”
visual diagrams depicting the Spark API under the MIT license to the Spark community. Jeff’s original, creative work can be found here and you can read more about
What is SPARK (II) • Three modes of execution – Spark shell – Spark scripts – Spark code • API defined for multiple languages – Scala – Python – Java A couple of words on Scala • Object-oriented language: everything is an object and every operation is a method-call. • Scala is also a functional language – Functions are first class values – Can be passed as arguments to
22/11/2015 · By http://www.HadoopExam.com For Full length Apache Spark Session , Please visit www.HadoopExam.com.
Learning Spark O’Reilly Media
Big Data Frameworks Scala and Spark Tutorial cs.helsinki.fi
these data analysis transformations and actions through an interactive terminal, which comes packaged with Spark. Spark driver programs run at a central location and oper-
The Essential Apache Spark Developer Cheat Sheet Apache Spark is a powerful open source processing engine built around speed, ease of use, and sophisticated analytics. This developer cheat sheet dives into resources for Spark developers, and includes a list of Spark transformations, actions, and persistence methods.
This Lecture” Programming Spark” Resilient Distributed Datasets (RDDs)” Creating an RDD” Spark Transformations and Actions” Spark Programming Model”
Key constructs: Resilient Distributed Datasets (RDDs), Transformations, Actions, Spark Driver programs, SparkContext and how applications deployed to a Spark cluster utilize the parallel nature of Spark.
Spark Core Spark Streaming MLlib GraphX RDD API DataFrames API and Spark SQL Workloads . Driver Program Ex RDD W RDD T T Ex RDD W RDD T T Worker Machine Worker Machine . Resilient Distributed Datasets (RDDs) •Write programs in terms of operations on distributed data •Partitioned collections of objects spread across a cluster •Diverse set of parallel transformations and actions …
From 0 to 1 : Spark for Data Science with Python 4.3 (251 ratings) Pair RDDs are special types of RDDs where every record is a key value pair. All normal actions and transformations apply to these in addition to some special ones. Special Transformations and Actions 14:44 Pair RDDs are useful to get information on a per-key basis. Sales per city, delays per airport etc. Average delay per
Spark Driver is the program that runs on the master node of the machine and declares transformations and actions on data RDDs. In simple terms, driver in Spark creates SparkContext, connected to a given Spark Master. The driver also delivers the RDD graphs to Master, where the standalone
Feature extraction and transformation Used in selecting a subset of relevant features (variables, predictors) for use in model construction. Frequent pattern mining
The doctests serve as simple usage examples and are a lightweight way to test new RDD transformations and actions. The unittests are used for more involved testing, such as testing job cancellation. The unittests are used for more involved testing, such as testing job cancellation.
Transformations in RDD Actions in RDD Loading data in RDD Saving data through RDD Key-Value Pair RDD MapReduce and Pair RDD Operations Spark and Hadoop Integration-HDFS Handling Sequence Files and Partitioner Spark Hadoop Integration-Yarn . Chapter 6 : Spark Streaming And Mllib Spark Streaming Architecture First Spark Streaming Program Transformations in Spark Streaming Fault …
22/11/2015 · By http://www.HadoopExam.com For Full length Apache Spark Session , Please visit www.HadoopExam.com.
Spark Fundamentals II Building on your foundational knowledge of Spark, take this opportunity to move your skills to the next level. With a focus on Spark Resilient Distributed Data Set operations this course exposes you to concepts that are critical to your success in this field.
You go back to stage 1 (the spark), set (beyond SMART) goals, and prepare yourself for another transformation. Success is a result of daily actions… Design your daily checklist for high
Here is a cheat sheet that I put together that might help you out: Apache Spark Cheat Sheet (PDF) or Apache Spark Cheat Sheet (HTML) Transformations and Actions are the first two items listed. The benefit here is that Spark figures out what work MUST occur and …
What are DAG and Physical Execution Plan in Apache Spark
Fine grained transformation vs coarse grained transformations
Matei&Zaharia& & UC&Berkeley& & www.spark4project.org&& Advanced(Spark Features(UC&BERKELEY&
Databricks would like to give a special thanks to Jeff Thomspon for contributing 67 visual diagrams depicting the Spark API under the MIT license to the Spark
Everyone will receive a username/password for one of the Databricks Cloud shards. Use your laptop and browser to login there.! We find that cloud-based notebooks are a simple way
6sdun 2yhuylhz *rdo hdvlo zrun zlwk odujh vfdoh gdwd lq whupv ri wudqvirupdwlrqv rq glvwulexwhg gdwd 7udglwlrqdo glvwulexwhg frpsxwlqj sodwirupv vfdoh zhoo exw kdyh olplwhg ,v
Actions: Actions refer to an operation which also applies on RDD, that instructs Spark to perform computation and send the result back to driver. This is an example of action. This is an example of action.
Transformation and action. In previous blog you know that transformation functions produce a new Resilient Distributed Dataset (RDD). Resilient distributed datasets are Spark’s main programming
A fine grained update would be an update to one record in a database whereas coarse grained is generally functional operators (like used in spark) for example map, reduce, flatMap, join.
3.1.3 SparkCL Transformations and Actions Standard Spark actions such as Map and transformations such as Reduce needed to be ported to the new framework.
Apache Spark Cheat Sheet MapR
Apache Spark Course Content credosystemz.com
Spark is lazy, so nothing will be executed unless you call some transformation or action that will trigger job creation and execution. Look at the following snippet of the word-count example. Look at the following snippet of the word-count example.
The structure of a Spark program at higher level is – RDD’s are created from the input data and new RDD’s are derived from the existing RDD’s using different transformations, after which an action is performed on the data. In any spark program, the DAG operations are created by default and whenever the driver runs the Spark DAG will be converted into a physical execution plan.
Code Snippet1 work’s fine and populates the database…the second code snippet doesn’t work.we are newbie’s to spark and would love to know the reason behind it and the way to get it working ?…..the reason we are experimenting ( we know it’s a transformation and foreachRdd is an action) is foreachRdd is very slow for our use case with heavy load on a cluster and we found that map is …
visual diagrams depicting the Spark API under the MIT license to the Spark community. Jeff’s original, creative work can be found here and you can read more about
PySpark Internals Spark – Apache Software Foundation
DICE Verification Tools Final Version
This is 2nd post in Apache Spark 5 part blog series. In the previous blog we looked at why we needed tool like Spark, what makes it faster cluster computing system and its core components. In this blog we will work with actual data using Spark core API: RDDs, transformations and actions. RDD
This Lecture Resilient Distributed Datasets (RDDs) Creating an RDD Spark RDD Transformations and Actions Spark RDD Programming Model Spark Shared Variables
these data analysis transformations and actions through an interactive terminal, which comes packaged with Spark. Spark driver programs run at a central location and oper-
Dig in and get your hands dirty with one of the hottest data processing engines today. A great guide. Jonathan Sharley, Pandora Media. Spark in Action teaches you the theory and skills you need to effectively handle batch and streaming data using Spark.
Spark is lazy, so nothing will be executed unless you call some transformation or action that will trigger job creation and execution. Look at the following snippet of the word-count example. Look at the following snippet of the word-count example.
visual diagrams depicting the Spark API under the MIT license to the Spark community. Jeff’s original, creative work can be found here and you can read more about
functions to Spark’s transformations and actions In Java, we pass objects of the classes that implement one of the Spark’s function interfaces Each class implementing a Spark’s function interface is characterized by the call method The call method contains the “function” that we want to pass to a transformation or to an action 42 . 10/04/2018 22 There are many Spark’s function
Spark Driver is the program that runs on the master node of the machine and declares transformations and actions on data RDDs. In simple terms, driver in Spark creates SparkContext, connected to a given Spark …
Spark SQL Overview. Spark SQL integrates relational processing with Spark’s functional programming. It provides support for various data sources and makes it possible to weave SQL queries with code transformations thus resulting in a very powerful tool.
Actions are operations (such as reduce, count, first, and so on) that return a value after running a computation on an RDD. Transformations in Spark are “lazy”, meaning that they do not compute their results right away. Instead, they just “remember” the operation to be performed and the dataset (e.g., file) to which the operation is to be performed. The transformations are only
Figure 8 shows how Apache Spark executes a job on a cluster The Master controls how data is partitioned, and it takes advantage of data locality while keeping track …
functions to Spark’s transformations and actions In Java, we pass objects of the classes that implement one of the Spark’s function interfaces Each class implementing a Spark’s function interface is characterized by the call method The call method contains the “function” that we want to pass to a transformation or to an action There are many Spark’s function interfaces The
Feature extraction and transformation Used in selecting a subset of relevant features (variables, predictors) for use in model construction. Frequent pattern mining
With Spark, you can tackle big datasets quickly through simple APIs in Python, Java, and Scala. This edition includes new information on Spark SQL, Spark Streaming, setup, and Maven coordinates. This edition includes new information on Spark SQL, Spark Streaming, setup, and Maven coordinates.
Spark Driver is the program that runs on the master node of the machine and declares transformations and actions on data RDDs. In simple terms, driver in Spark creates SparkContext, connected to a given Spark Master. The driver also delivers the RDD graphs to Master, where the standalone
Apache Spark Introduction Examples and Use Cases Toptal
Big Data Analysis with Apache Spark edX
Spark concepts such as the Resilient Distributed Dataset (RDD), interacting with Spark using the shell, implementing common processing patterns, practical data engineering/analysis approaches using Spark…
Spark SQL Overview. Spark SQL integrates relational processing with Spark’s functional programming. It provides support for various data sources and makes it possible to weave SQL queries with code transformations thus resulting in a very powerful tool.
The structure of a Spark program at higher level is – RDD’s are created from the input data and new RDD’s are derived from the existing RDD’s using different transformations, after which an action is performed on the data. In any spark program, the DAG operations are created by default and whenever the driver runs the Spark DAG will be converted into a physical execution plan.
Types of spark operations There are Three types of operations on RDDs: Transformations, Actions and Shuffles. The most expensive operations are those the require
From 0 to 1 : Spark for Data Science with Python 4.3 (251 ratings) Pair RDDs are special types of RDDs where every record is a key value pair. All normal actions and transformations apply to these in addition to some special ones. Special Transformations and Actions 14:44 Pair RDDs are useful to get information on a per-key basis. Sales per city, delays per airport etc. Average delay per
Spark is lazy, so nothing will be executed unless you call some transformation or action that will trigger job creation and execution. Look at the following snippet of the word-count example. Look at the following snippet of the word-count example.
What is SPARK (II) • Three modes of execution – Spark shell – Spark scripts – Spark code • API defined for multiple languages – Scala – Python – Java A couple of words on Scala • Object-oriented language: everything is an object and every operation is a method-call. • Scala is also a functional language – Functions are first class values – Can be passed as arguments to
functions to Spark’s transformations and actions In Java, we pass objects of the classes that implement one of the Spark’s function interfaces Each class implementing a Spark’s function interface is characterized by the call method The call method contains the “function” that we want to pass to a transformation or to an action There are many Spark’s function interfaces The
visualapi spark Apache Spark Data Management
Spark map vs foreachRdd Stack Overflow
Matei&Zaharia& & UC&Berkeley& & www.spark4project.org&& Advanced(Spark Features(UC&BERKELEY&
Here is a cheat sheet that I put together that might help you out: Apache Spark Cheat Sheet (PDF) or Apache Spark Cheat Sheet (HTML) Transformations and Actions are the first two items listed. The benefit here is that Spark figures out what work MUST occur and …
functions to Spark’s transformations and actions In Java, we pass objects of the classes that implement one of the Spark’s function interfaces Each class implementing a Spark’s function interface is characterized by the call method The call method contains the “function” that we want to pass to a transformation or to an action 42 . 10/04/2018 22 There are many Spark’s function
This Lecture Resilient Distributed Datasets (RDDs) Creating an RDD Spark RDD Transformations and Actions Spark RDD Programming Model Spark Shared Variables
It is essential you are comfortable with the Spark concepts of Resilient Distributed Datasets (RDD), Transformations, Actions. If you need more information on these subjects from a non-Scala point of view, it is suggested to start at the Spark Tutorial page first and then return to this page. In the following tutorials, the Spark fundaments are covered from a Scala perspective.
Spark SQL Overview. Spark SQL integrates relational processing with Spark’s functional programming. It provides support for various data sources and makes it possible to weave SQL queries with code transformations thus resulting in a very powerful tool.
these data analysis transformations and actions through an interactive terminal, which comes packaged with Spark. Spark driver programs run at a central location and oper-
Apache Spark Course Content credosystemz.com
Apache Spark GitHub Pages
Code Snippet1 work’s fine and populates the database…the second code snippet doesn’t work.we are newbie’s to spark and would love to know the reason behind it and the way to get it working ?…..the reason we are experimenting ( we know it’s a transformation and foreachRdd is an action) is foreachRdd is very slow for our use case with heavy load on a cluster and we found that map is …
Transformations in RDD Actions in RDD Loading data in RDD Saving data through RDD Key-Value Pair RDD MapReduce and Pair RDD Operations Spark and Hadoop Integration-HDFS Handling Sequence Files and Partitioner Spark Hadoop Integration-Yarn . Chapter 6 : Spark Streaming And Mllib Spark Streaming Architecture First Spark Streaming Program Transformations in Spark Streaming Fault …
This Lecture Resilient Distributed Datasets (RDDs) Creating an RDD Spark RDD Transformations and Actions Spark RDD Programming Model Spark Shared Variables
The transformations are only computed when an action requires a result to be returned to the driver program. With these two types of RDD operations, Spark can run more efficiently: a dataset created through map() operation will be used in a consequent reduce() operation and will return only the result of the the last reduce function to the driver.
I tried out the transformations and actions but most importantly had fun while doing so because of the little notes of humor that you had left in between. I’m glad google led …
At a high level, every Spark application consists of a driver program that runs the user’s main function and executes various parallel operations on a cluster. The main abstraction Spark provides is a distributed dataset, which is a collection of elements partitioned across the nodes of the cluster
Spark SQL Overview. Spark SQL integrates relational processing with Spark’s functional programming. It provides support for various data sources and makes it possible to weave SQL queries with code transformations thus resulting in a very powerful tool.
SQL queries can be easily translated into Spark transformation and actions, as demonstrated in Shark and Spark SQL. In fact, many primitive transformations and actions are …
Spark is lazy, so nothing will be executed unless you call some transformation or action that will trigger job creation and execution. Look at the following snippet of the word-count example. Look at the following snippet of the word-count example.
Spark 2.4.0 is built and distributed to work with Scala 2.11 by default. (Spark can be built to work with other versions of Scala, too.) To write applications in Scala, you will need to use a compatible Scala version (e.g. 2.11.X).
Spark Fundamentals II Building on your foundational knowledge of Spark, take this opportunity to move your skills to the next level. With a focus on Spark Resilient Distributed Data Set operations this course exposes you to concepts that are critical to your success in this field.
Transformations, Actions, Laziness Actions cause the execution of the query. What, exactly does “execution of the query” mean? It means: •Spark initiates a distributed read of the data source •The data flows through the transformations (the RDDs resulting from the Catalyst query plan) •The result of the action is pulled back into the driver JVM. 25. All Actions on a DataFrame 26. 27. 28
Matei&Zaharia& & UC&Berkeley& & www.spark4project.org&& Advanced(Spark Features(UC&BERKELEY&
Ans: An action is an operation that triggers execution of RDD transformations and returns a value (to a Spark driver – the user program). They trigger execution of RDD transformatio ns to
The book starts with an introduction to Spark, after which the Spark fundamentals are introduced. In practical terms, this means the spark-in-action VM, using the Spark shell and writing apps in Spark, the basics of RDD (resilient distributed dataset) actions, transformations, and double RDD functions.
Spark provides two kinds of operations, one is transformation and another is action. Transformation and Actions What is Transformation: Transformation converts one RDD to another RDD.
Intro to DataFrames and Spark SQL piazza-resources.s3
functions to Spark’s transformations and actions In Java, we pass objects of the classes that implement one of the Spark’s function interfaces Each class implementing a Spark’s function interface is characterized by the call method The call method contains the “function” that we want to pass to a transformation or to an action 42 . 10/04/2018 22 There are many Spark’s function
Apache Spark flatmap Transformation Tutorial YouTube
Spark Programming Guide · mesos/spark Wiki · GitHub
Prerequisite Tutorials Point